A Real Scenario Machine Learning Question

Recently I got a real scenario machine learning question, which does not have existing models. I would like to record my thoughts here which may save my time later.
Here is the question:
A company receives thousands of documents everyday uploaded by our users. Generally these documents are invoices or bills. We would like to extract the vendor and amount from these documents automatically (i.e. using software rather than human inspection).
They store the following pieces of information for each document:
- The pdf document uploaded by the user (please see example.pdf attached)
- The text extracted from that pdf (please see example.txt attached - Note: often the extracted text would not be in an order that seems natural to a human reader)
- Labels of what the vendor and amount should be for each document (in the attached example, vendor would be “Marketing Fuel Biz.”, and amount would be “747.50”).
Question: Describe a machine learning solution to this problem.
Additon: Some percentage of the stored labels may be incorrect. What would you change to mitigate this problem.
The sample pdf and OCR output txt is downloadable.
Intuitive Thoughts
As the OCR result loses the invoice position information (sample txt file), the traditional NLP methods, which expect sequential structure, would not work on such text corpus [1]. So my proposed solution would focus on rebuilding the invoice structure information.
Based on my understanding, the invoice structure follows a certain pattern, such as the left top area is vendor logo/name and the total amount is in the bottom right. There are definitely some special cases, but the prior statement is an assumption of my solution.
In order to track the position in a PDF file (could be easily convert to an image file), the convolutional neural networks (CNN) [2] could fit this task, it has been proved successfully on many image processing tasks [3, 4, 5]. Although a paper [6] states to extract invoice info from the recurrent neural network (RNN), their input is words and positions (in our case, we do not have positions). So I propose to use Faster R-CNN [4] or YOLO [7] to solve the problem, they both are mature models of object detection and applied in many products.
The CNN model input should be images, and outputs are labels and region coordinate (the format would be like {vendor, 5, 15, 20, 40}).
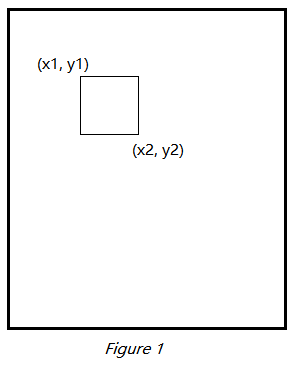
Therefore, we need a dataset to train the CNN model. Since we already have the original PDF files and labels of vendor/amount, we could generate an image dataset for training the model. For each training entry, it contains an image converted from PDF and a region info of vendor/amount. The region info is the coordinate of two points which consist of a rectangle (e.g. (x1, y1) and (x2, y2) in figure 1). The dataset generation process could be done via a method of ORC and image process combination. The method is cropping the image into multiple rectangles (moving windows), then apply ORC on each rectangle. Based on the text outputs of rectangles, the area contains only vendor name is labeled as vendor, and the areas contain the amount are labeled as amount.
After we have the dataset, we split it into training and testing datasets. The split ratio could be 80/20 [8].
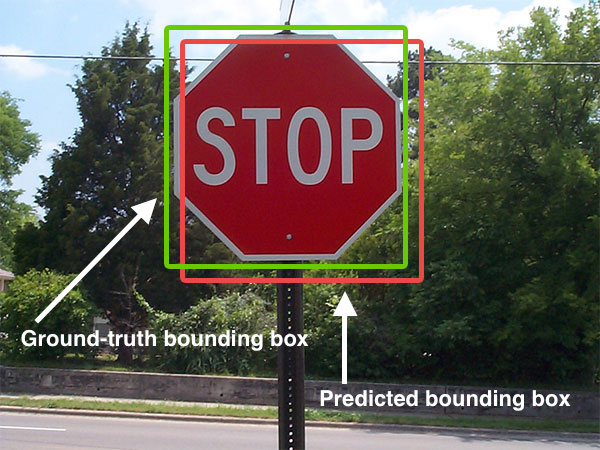
The evaluation metric is mean precision average (mPA) at the different intersection over union (IoU) thresholds. The IoU of a proposed set of object pixels and a set of true object pixels is calculated as IoU(A,B)=A∩B/A∪B (image below [9]). The metric sweeps over a range of IoU thresholds, at each point calculating an average precision value. The threshold values range from 0.5 to 0.95 with a step size of 0.05: (0.5, 0.55, 0.6, 0.65, 0.7, 0.75, 0.8, 0.85, 0.9, 0.95). In other words, at a threshold of 0.5, a predicted object is considered a “hit” if its intersection over union with a ground truth object is greater than 0.5. At each threshold t, we can check if it “hit” on the ground truth. Then the mPA is 1/thresholds∑hit(t).
When the model training finished (let’s assume it meets our expectation), we could apply a post process to convert the result to our label. We will get the region coordinate from the model output, and based on the coordinate, we can crop the rectangle and feed it to OCR. It is the final result. Then we can compare the predicated labels with our ground truth in the database to evaluate the model performance (the evaluation metric could be precision on both labels).
Here is the overview of the proposed solution:
Convert PDF to Image -> Dataset Preparation -> CNN Model -> OCR -> Results
To mitigate the impact of incorrect labels, we could add an extra step in dataset preparation. By calculating the frequency of each vendor label in the dataset, we could remove those entries with label frequency lower than a threshold. This is based on an assumption that incorrect labels cannot occur multiple times (the threshold) with the same value.
Failure on the Intuitive Thoughts
I set up an experiment for the solution, which trained YOLOv3 [10] (pre-trained on ImageNet [11]) with 30 manually labeled invoices images (google searched images, each invoice contains vendor, logo, and amount labels). Although the predicated labels on validation dataset look promising, the mAP is almost zero on the test dataset. The reason for the low performance may be caused by the principle of CNN, the CNN only can learn the features that appear in the training set. The way to improve the model would be training on a larger dataset and assume it covers all test cases. Therefore, I would like to propose two new solutions for the ML question.
- Using the Recurrent Neural Network (RNN) with Long Short-Term Memory cells (LSTM) [12].
- Using the Reinforcement Learning (RL) [13].
RNN
I reviewed the example.txt file, it doesn’t fully unorganized. We could recognize some patterns from it, like it reads column by column, not row by row as human do. Although RNN is good at the sequential data, due to the gradient vanishing problem, it won’t work for long sentence. So the LSTM method came up, bring the ability to memory long distance relationship to RNN. For example, “A cat jumps on the table, it breaks a cup, so we chase it off the table” which “it” represents the “cat” in the previous phrase. It may be easy to identify the first “it” as the cat because they are close, but for the second “it”, it’s hard to tell which it represents (cat, table, or cup).
As we are processing the text data, we need a preprocessing step to clean up. First, remove punctuation marks, like semi-colon, colon, exclamation mark, and etc. But keep the period and comma, because they may use in numbers. Second, tokenize the words, we could build up a vocabulary dictionary and convert each word into it represented the index in the dictionary. For unknown word and numbers, we use [UNK] and [NUM] instead. Finally, clear up the common words which do not help for our task, like the word “invoice”, it appears in every invoice.
Then we could feed the data to the RNN model. The RNN model supports many to many. Input is word sequence, and the output is the all possible labels for vendor/amount.
The evaluation metric would be the F1 measurement [14], which combines the precision and recall.
RL
When AlphaGo [15] defeats the world champion Lee Sedol, reinforcement learning becomes a hot topic in AI domain. The reinforcement learning is an algorithm to make AI compete with AI, the best set of policies is searched out during the competition. It has successfully applied to robotics, game playing, fintech, and ect. [16]
The reason I pick up the RL is the intuitive thought in my previous email. For a human, it is easy to identify vendor and amount by a glance, so the images contain all the info we need. Therefore, I think it is not necessary to take an extra step to convert the images to text, which lose information and create an extra layer to process.
So the idea is to find out the areas in invoice images which represent vendor and amount, then apply OCR against those areas to get final text formatted outputs.
Preprocess input documents to convert them into greyscale images.
Before we feed images into RL model, we need to set up rules for the agents, like identify the correct item plus points, identify the logo get some point, output wrong result get minus points. Then the RL model could brute force to find the best policies, like font size, bold style, and etc.
The RL model output should be the rectangle area of the vendor/amount. Then apply OCR to convert them to text.
The evaluation metric should be same as above, using the F1 score.
More
In addition to the above methods, I also thought about the generative adversarial networks (GANs) [17], but the tuning process is more like mystery comparing other models. Moreover, I found a paper [18] that using the deep CNN model to classify document images based their structure. In our case, I think we could use the similar approach to identify vendors, but we still need more info to retrieve the amounts.
BTW, besides the machine learning models, I wonder we also could improve the OCR to include the structure information in the output, like the PDF to HTML [18] and Zonal OCR [19]. If the company mainly deal with PDF files. As the PDF format specification [20] is open to the public, we could analysis PDF files directly, this would be another story.